1. 중단 없는 서비스 지원 위한 HA(High Availability)의 개요
가. HA(High Availability)의 정의
- 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질
나. HA의 필요성
| 장애 유연성 | 장애 발생 시 서비스 중단 최소화(99.999% Five Nine) |
| 서비스 연속성 | 기업의 Mission Critical한 업무에 대한 지속적인 서비스 필요성 증대 |
| Semi-FT시스템 | 고비용의 결함허용시스템(FT) 대안 |
2. HA의 구성체계, 구성요소, 유형
- HA의 구성 체계 (구성도)

- HA 구성에 참여하는 각 시스템은 2 개 이상의 N/W Card 를 가지면서 NW 통해 상호모니터링
- Standby N/W 은 Service N/W 장애 시 백업용으로 사용되고, Private N/W은 HA 에 참여하는
시스템들만 통신하는 전용 N/W으로 구성(Heart-Bit N/W)
- 외장 Disk 는 복수개의 시스템에서 공유할 수 있어야 하며, Concurrent access 또는 순차적인
Access 방식에 따라 HA가 다르게 구성(A-A, A-S)
나. HA의 구성요소
| 구성요소 | 설명 |
| 프로세서 | - CPU Dynamic Deal location: SMP 시스템과 같이 CPU가 여러 개인 경우, CPU의 상태를 점검하여 장애가 발생하는 경우 Online중에 장애 발생 CPU에서 수행중인 업무를 다른 정상적인 CPU로 넘기고 장애가 발생한 CPU를 중단시키는 기능 - HA 솔루션을 이용한 클러스터 구성: 멀티 컴퓨터 구성에서 Primary 노드가 다운되는 경우 Backup 노드가 자원과 업무를 넘겨받아 서비스를 수행하는 구성 |
| 메모리 | - ECC (Error Checking and Correction): 패리티 비트 등을 이용하여 메모리상의 에러를 검출하고 수정하는 기술 |
| 디스크 저장 장치 |
- RAID 기술을 이용한 고가용성 기술 - Twin-Tailed 디스크 구성: RAID를 이용하는 경우 디스크 자체의 장애에 대한 대비책은 있으나, 디스크가 장착된 서버가 다운되는 경우의 대책은 없다. 그런 경우에는 HA 클러스터 서버들에 디스크를 Twin-Tailed 방식으로 구성하여 한 서버가 다운되는 경우 그 서버의 디스크들을 백업 서버에 넘겨 계속 서비스가 되게 하는 방법이 사용된다 - SAN 기술을 이용하여 디스크를 서버와 별도로 구성함으로써 서버의 장애를 디스크와 분리한다 |
| 네트워크, I/O 어댑터들 |
- HA 솔루션을 이용하여 어댑터 자원을 중복화하고 장애가 나는 경우 IP 어드레스를 Take-over하거나, Dynamic Path Optimization 등의 기능을 통해 장애에 대한 대비책을 마련한다. - Hot-Pluggable 어댑터: 시스템 운영중에 장애 어댑터들을 교체할 수 있는 기술 |
| 전원 장치 | - N+1 구성: 여분의 Power Supply 구성 - UPS (Uninterrupted Power Supply): 정전 대비 기능 |
| 네트워크 연결 | - Multi-Homed 네트워크 연결: 여러 네트워크 경로를 준비하여 장애에 대비 |
| 서비스 프로세서 | - 시스템 상황을 감지하고 장애에 대한 기술적 지원을 위해 사용되는 별도의 프로세서 - 장애가 발생하면 모뎀을 통해 자동으로 장애를 통보 - 모뎀 등을 통해 원거리 지역의 시스템을 모니터링하고, 장애에 대한 기술적 지원 업무도 수행 |
| 재난대비 솔루션 | - 한 지역에 지진, 홍수 등의 재난이 발생하는 경우를 대비한 솔루션 - 대개 LAN 상에서 구현되는 HA 솔루션을 WAN 상으로 확장한 솔루션 이용 - 다른 지역에 백업 데이터 센터를 두어 재난에 대한 대비 |
다. HA 구성의 유형
| HA 유형 | 특성 | 구성 |
| Hot Standby |
- Active-Standby 구성 (가동시스템-백업시스템) - 시스템 자원 활용성 낮음 - 외장 스토리지는 가동시스템만 접근 |
|
| Mutual Takeover |
- 각각 다른 2가지 업무를 가진 독립된 시스템 장애 대비용 - 두 대의 서버가 서로 상대방 작업 인계 - 외장 스토리지는 해당 업무 시스템에서만 접근 가능 |
|
| Concurrent Access |
- 여러 개의 시스템이 동시에 업무를 병렬로 처리하는 방식(All Active) - Fail-Over 시간이 빠름 - 자원의 효율적인 이용 가능 - 동일한 데이터베이스를 두 대 이상의 서버가 공유하여 사용 |
3. HA의 동작 방식
가. 시스템 전체 장애 발생 시
- 장애 복구 시간 : IP Address Takeover Time + Disk Takeover Time + Application Takeover Time
단, 사용 Application에 따라 차이 발생함 (일반적으로 30초 ~ 300초 이내)
- 한 시스템으로부터 keep alive packet 이 전혀 오지 않는 경우 백업시스템은 상대 시스템이 Down 되었다고 판단하고 이미 정의된 자원(Volume Group, File systems, IP Address, Application)을 Failover
- Failover 순서 : 미리 정의된 Scripts 에 의해 Network 자원 → Disk 자원 → Application 자원 순서로 진행됨

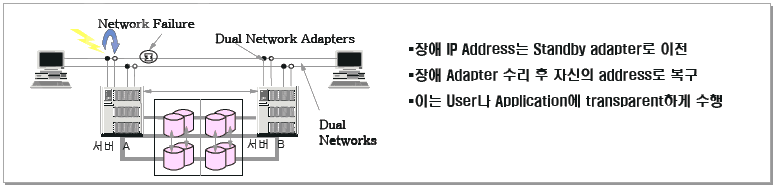
나. Network Adapter(Card) 장애 발생시
- 장애 복구 시간 : Address Swapping Time
- 대부분 Network 상태 점검을 위한 Grace Time이 차지함 (일반적으로 60초 이내)
1) 가동 시스템 내의 Service Adapter 장애 시
- 시스템에 Service adapter와 Standby adapter를 설치 구성한 경우, Service adapter 에 장애가 발생하면 Standby adapter 가 Service adapter 의 IP Address 를 Fail-over
2) 가동 시스템 내의 전체 N/W Adapter 장애 시
- 백업 시스템의 Standby Adapter 로 가동 시스템의 Service IP Address 가 Failover 됨.
다. TCP/IP Network 장애 발생 시
- Adapter 장애와 구별하여 HA는 장애 처리를 하지 않고 대기함
- Network 전체장애가 발생하는 경우에는 특별한 동작을 하지 않는다
- N/W 전체 장애 시에는 백업 시스템으로 Failover 해도 동일한 N/W 문제가 존재함

라. 스토리지(Disk) 장애 발생 시
- HA는 특별한 조치를 취하지 않음
- Disk Subsystem의 기능인 RAID 기능에 의하여 복구됨
단, RAID0 또는 RAID 미구성시 데이터 복구 불가함

4. HA(High Availability)와 FT(Fault Tolerant System) 비교 및 HA의 한계점
가. HA와 FT의 비교
| 항목 | HA | FT |
| Fault Time | 30 ~ 300초 | 0초 |
| Concurrent 유지보수 | 불필요 | 필수 |
| 동일성능가격 | 2배 이상 | 10~20배 |
| 응용프로그램 | 범용 제품 활용가능 | 제한적인 프로그램 |
| OS/HW | 범용 OS / 범용 HW | 전용 OS / 전용 HW |
나. HA의 한계점 및 구축 시 고려사항
| HA 한계점 | 극복방안 |
| - 외장 디스크 장애 시 HA 솔루션으로 해결 불가 - 시스템 Hang 발생시 Fail-Over 불가 - 시스템 성능저하에 대해 대응 불가 - DB 또는 App Down시 일반적으로 Fail-Over 불가 - HA 구성에 따른 정보교환으로 시스템 안정성, 보안성, 성능에 오버헤드 존재함 |
- 외장디스크 또는 스토리지는 최소 RAID5 구성- Disk의 물리적인 Fault에 대비한 Hot Spare 구성 - Heart Bit을 통해 서비스 포트 응답 Check - 스토리지의 정기적인 백업 관리 철저 - 운영자 및 Operator 교육/훈련 |
'IT 이야기 > Software Engineering' 카테고리의 다른 글
| Refactoring (마틴 파울러 책 기반) (2) | 2023.09.26 |
|---|---|
| 전사관점의 프로젝트 통합 관리 조직, PMO의 개요 (1) | 2023.09.20 |
| i-node의 개요 및 구조 (0) | 2023.09.19 |
| 크립토재킹의 정의와 공격 방식 (0) | 2023.09.19 |
| [CA] RAID 개념 정리 (0) | 2023.08.25 |


